-
2023-02-20
Why I am co-organizing FediForum
Kaliya Young (identitywoman), Jennifer Holmes and I are organizing a new unconference focused on the Fediverse and the future of social media:

Like many, I have been watching the destruction of Twitter by its new owner with utter fascination. If it was problematic in many ways before, Musk-Twitter is far worse, and there are no signs it will ever return to the state that many of us, myself included, mostly enjoyed.
Fortunately, there are alternatives, led by Mastodon and a rapidly-growing list of Fediverse apps that all interoperate thanks to a number of open protocols such as WebFinger, ActivityPub and Activity Vocabulary. Millions of people have created accounts there in recent months, and over a million new users have become regulars.
But there are growing pains and many open questions, such as:
- The underlying protocol standards are currently essentially unmaintained, and real-implementations don’t exactly match how the standards were intended. How will this situation be resolved?
- How do we create and maintain a safe space for traditionally disenfranchised people?
- The Fediverse currently depends on much unpaid volunteer work. How long can that go well? What if another million users (or more!) join, and the novelty effect wears off?
- Should brands be allowed in?
- Is #Fediblock the best we can do for moderation?
- How do we keep the character of the place if (when!) large organizations come in that bring lots of new users, and, in comparison, large budgets?
- Who decides?
Conversations need to be had, in a form that encourages problem solving. That’s the kind of space we are trying to create with FediForum: where people meet who want to move the Fediverse forward: on technology, on funding, on operations, on governance, and perhaps on culture.
Because if we don’t, there’s a real chance the once-in-a-generation opportunity to build better social media passes, and I really, really don’t want that to happen. I hope you don’t either.
So, if you love Mastodon or any other post-Twitter social media apps, and have an opinion on the future of social media, join us and help figure it out together with others who think similarly. The first event will be on-line; we hope to be able to do an in-person event later this year.
More info: FediForum.org
-
2023-01-29
What if Apple’s headset is a smashing success?
Signs are pointing that Apple will announce its first headset in the next few months. This would be a major new product for Apple – and the industry beyond –, but there is very little excitement in the air.
We can blame Meta for that. After buying Oculus, iterating over the product for almost 9 years since, and reportedly spending more than $10 billion a year on it, their VR products remains a distinct Meh. I bought a Quest 2 myself, and while it definitely has some interesting features (I climbed Mt Everest, in VR!), it mostly sits on the shelf, gathering dust.
So the industry consensus is that Apple’s won’t amount to much either. If Meta couldn’t find compelling use cases, the thinking goes, Apple won’t either, because there aren’t any! (Other than some limited forms of gaming and some niche enterprise ones.)
I think this line of thinking would be a mistake.
My argument: Apple understands their customers and works down their use cases better than anybody. If Apple works on a new product category for many years – and signs are that they have – and then finally decides that the product is ready, chances are, it is. Their track record on new products is largely unblemished since the return of Jobs about 25 years ago:
- fruity fun design for a computer (iMac) – success
- digital music player (iPod) – smashing success
- smartphone (iPhone) – so successful it killed and reinvented an entire industry
- table (iPad) – success
- watch (iWatch) – success
- … and many smaller products, like headsets, voice assistance, Keynote etc.
Looking for a major dud in those 25 years, I can’t really find one. (Sure, some smaller things like the 25-year anniversary Mac – but that was always a gimmick, not a serious product line.)
It appears that based on their history, betting against Apple’s headset is not a smart move. Even if we can’t imagine why an Apple headset would be compelling before we see it: we non-Apple people didn’t predict iPhone either, but once we saw it, it was “immediately” obvious.
So let’s turn this around. What about we instead assume the headset will be a major success? Then what?
I believe this would transform the entire technology industry profoundly. For historical analogies, I would have to go back all the way to the early 80’s when graphical user interfaces first became widely used – coincidentally (or not) an Apple accomplishment: they represented a fundamentally different way of interacting with computers than the text terminals that came before them. Xerox Parc gave that demo to many people. Nobody saw the potential and went with it, just Apple did. And they pulled a product together that caused the entire industry to transform. Terminals are still in use, but only by very few people for very specific tasks (like system administrators).
What if AR/VR interfaces swept the world as the GUI swept the PC?
I believe they can, if somebody relentlessly focuses on uses cases and really makes them work. I built my first 3D prototype in VRML in 1997. It was compelling back then and it would be today. Those uses can be found, I’m quite certain.
Based on everything we’ve seen, it’s clear that Meta won’t find them. Hanging out with your friends who don’t look like your friends in some 3D universe is just not it. But if anybody can do it, it’s Apple.
So I’m very much looking forward to seeing what they came up with, and I think you should be, too.
-
2023-01-24
Activity Streams graphical model
All you need is a gazillionaire doing strange things to some internet platform, and all of a sudden decentralized social media soars in adoption. So lots of people are suddenly seriously looking at how to contribute, myself included.
Core to this is the ActivityPub standard, and real-world implementations that mix it with additional independently defined protocols, such as what Mastodon does.
None of them are particularly easy to understand. So I did a bit of drawing just to make it clearer (for myself) what kind of data can be shipped around in the Fediverse. To be clear, this is only a small part of the overall stack, but an important one.
Here are some diagrams. They are essentially inheritance diagrams that show what kinds of activities there are, and actors, etc. Posted here in case they are useful for others, too.
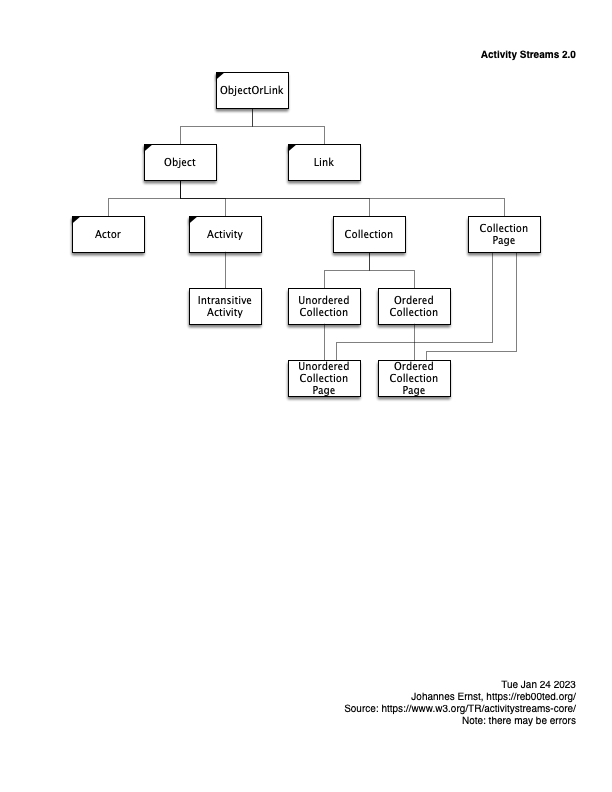
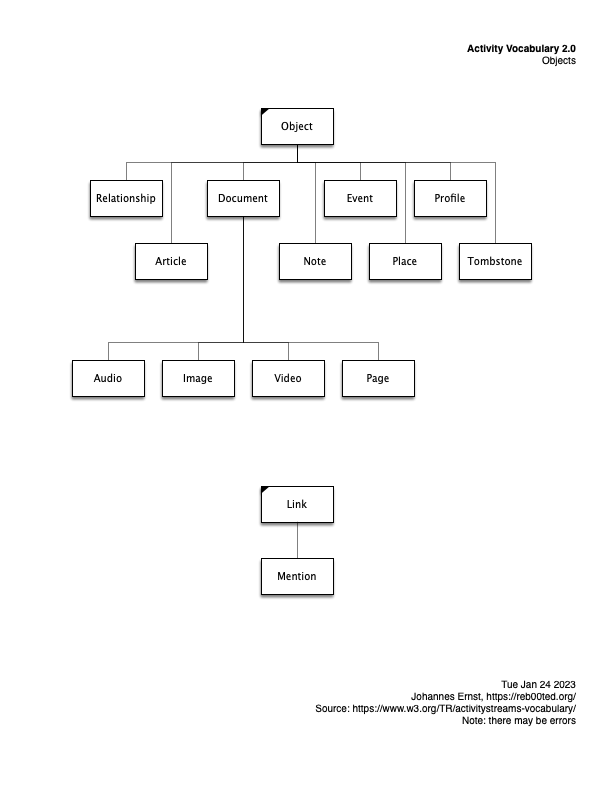
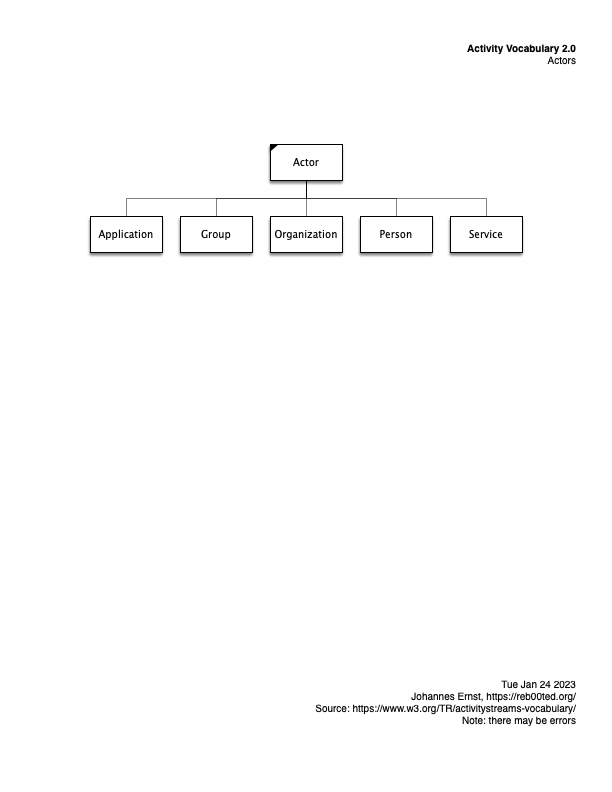
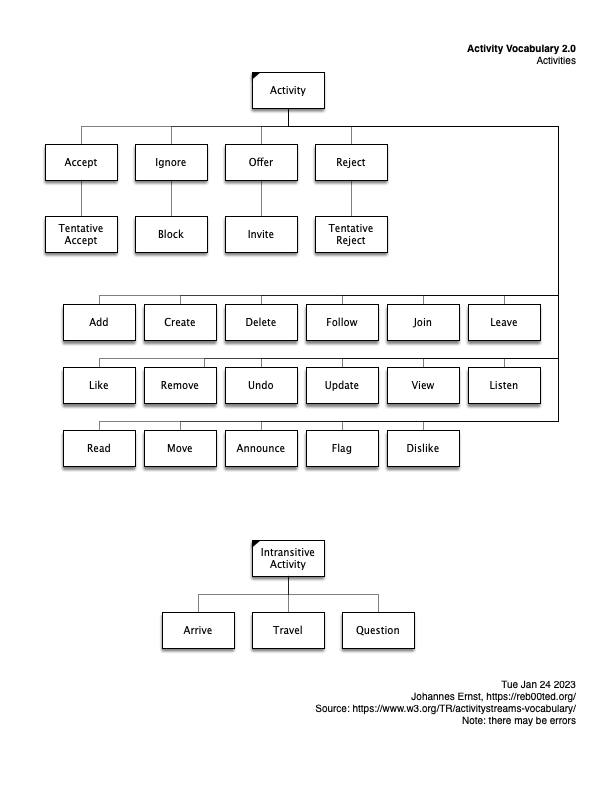
And here’s how to interpret my homegrown graphical notation. (I made it up for my dissertation eons ago, and used it ever since. It has certain advantages over, say, UML or traditional ERA diagram styles. IMHO :-))

-
2022-11-01
California water prices have quadrupled
Why should other countries have all the fun with exploding prices for base resources, like heating in the UK, or all kinds of energy across Europe?
Nasdaq has an index for open-market wholesale prices for water in the US West, mostly California. Currently, it is in the order of a $1000 per acre-foot, while the non-drought price seems to be about $250.
Quadrupled.
![[Graph]](https://reb00ted.org/images/posts/20221101-water-prices-california.png)
Links: current prices, explanation.
-
2022-10-24
The Push-Pull Publish-Subscribe Pattern (PuPuPubSub, or shorter: P3Sub)
(Updated Dec 14, 2022 with clarifications and a subscriber implementation note.)
Preface
The British government clearly has more tolerance for humor when naming important things than the W3C does. Continuing in the original fashion, thus this name.
The Problem
The publish-subscribe pattern is well known, but in some circumstances, it suffers from two important problems:
-
When a subscriber is temporarily not present, or cannot be reached, sent events are often lost. This can happen, for example, if the subscriber computer reboots, falls off the network, goes to sleep, has DNS problems and the like. Once the subscriber recovers, it is generally not clear what needs to happen for the subscriber to catch up to the events it may have missed. It is not even clear whether it has missed any. Similarly, it is unclear for how long the publisher needs to retry to send a message; it may be that the subscriber has permanently gone away.
-
Subscriptions are often set up as part of the following pattern:
- A resource on the Web is accessed. For example, a user reads an article on a website, or a software agent fetches a document.
- Based on the content of the obtained resource, a decision is made to subscribe to updates to that resource. For example, the user may decide that they are interested in updates to the article on the website they just read.
- There is a time lag between the time the resource has been accessed, and when the subscription becomes active, creating a race condition during which update events may be missed.
While these two problems are not always significant, there are important circumstances in which they are, and this proposal addresses those circumstances.
Approach to the solution
We augment the publish-subscribe pattern in the following way:
-
All events, as well as the content of the resource whose changes are supposed to be tracked are time-stamped. Also, each event identifies the event that directly precedes it (that way, the subscriber can detect if it missed something). Alternatively, a monotonically increasing sequence number could be used.
-
The publisher stores the history of events emitted so far. For efficiency reasons, this may be shortened to some time window reaching to the present, as appropriate for the application; for example, all events in the last month. (Similar to how RSS/Atom feeds are commonly implemented.)
-
The publisher provides a query interface to the subscriber to that history, with a “since” time parameter, so the subscriber can obtain the sequence of events emitted since a certain time. (Actually, since “right after” the provided time not including the provided time itself.)
-
When subscribing, in addition to the callback address, the subscriber provides to the publisher:
- a time stamp, and
- a subscription id.
Further, the actual sending of an event from the publisher to the subscriber is considered to be a performance optimization, rather than core to the functionality. This means that if the event cannot be successfully conveyed (see requirements above), it is only an inconvenience and inefficiency rather than a cause of lost data.
Details
About the race condition
-
The future subscriber accesses resource R and finds time stamp T0. For example, a human reads a web page whose publication date is April 23, 2021, 23:00:00 UTC.
-
After some time passes, the subscriber decides to subscribe. It does this with the well-known subscription pattern, but in addition to providing a callback address, it also provides time stamp T0 and a unique (can be random) subscription id. For example, a human’s hypothetical news syndication app may provide an event update endpoint to the news website, and time T0.
-
The publisher sets up the subscription, and immediately checks whether any events should have been sent between (after) T0 and the present. (It can do that because it stores the update history.) If so, it emits those events to the subscriber, in sequence, before continuing with regular operations. As a result, there is no more race condition between subscription and event.
-
When sending an event, the publisher also sends the subscription id.
About temporary unavailability of the subscriber
-
After a subscription is active, assume the subscriber disappears and new events cannot be delivered. The publisher may continue to attempt to deliver events for as long as it likes, or stop immediately.
-
When the subscriber re-appears, it finds the time of the last event it had received from the publisher, say time T5. It queries the event history published by the publisher with parameter T5 to find out what events it missed. It processes those events and then re-subscribes with a later starting time stamp corresponding to the last event it received (say T10). When it re-subscribes, it uses a different subscription id and cancels the old subscription.
-
After the subscriber has re-appeared, it ignores/rejects all incoming events with the old subscription id.
Subscriber implementation notes
-
The subscriber receives events exclusively through a single queue for incoming events. This makes implementing an incoming-event handler very simple, as it can simply process events in order.
-
The event queue maintains the timestamp of the last event it successfully added. When a new event arrives, the queue accepts this event but only if the new event is the direct follower of the last event it successfully added. If it is not, the incoming event is discarded. (This covers both repeatedly received events and when some events were missed.)
-
The subscriber also maintains a timer with a countdown from the last time an event was successfully added to the incoming queue. (The time constant of the timer is application-specific, and may be adaptive.) When the timeout occurs, the subscriber queries the publisher, providing the last successful timestamp. If no updates are being found, nothing happens. If updates are being found, it is fair to consider the existing subscription to have failed. Then:
- The subscriber itself inserts the obtained “missed” events into its own incoming event queue from where they are processed.
- The subscriber cancels the existing subscription.
- The subscriber creates a new subscription, with the timestamp of the most recent successfully-inserted event.
Observations
-
Publishers do not need to remember subscriber-specific state. (Thanks, Kafka, for showing us!) That makes it easy to implement the publisher side.
-
From the perspective of the publisher, delivery of events to subscribers that can receive callbacks, and those that need to poll, both works. (It sort of emulates RSS except that a starting time parameter is provided by the client, instead of a uniform window decided on by the publisher as in RSS)
-
Subscribers only need to keep a time stamp as state, something they probably have already anyway.
-
Subscribers can implement a polling or push strategy, or dynamically change between those, without the risk of losing data.
-
Publishers are not required to push out events at all. If they don’t, this protocol basically falls back to polling. This is inefficient but much better than the alternative and can also be used in places where, for example, firewalls prevent event pushing.
Feedback?
Would love your thoughts!
-
-
2022-08-30
The 5 people empowerment promises of web3

Over at Kaleido Insights, Jessica Groopman, Jaimy Szymanski, and Jeremiah Owyang (the former Forrester “Open Social” analyst) describe Web3 Use Cases: Five Capabilities Enabling People.
I don’t think this post has gotten the attention it deserves. At the least, it’s a good starting framework to understand why so many people are attracted to the otherwise still quite underdefined web3 idea. Hint: it’s not just getting rich quick.
I want to riff on this list a bit, by interpreting some of the categories just a tad differently, but mostly by comparing and contrasting to the state of the art (“web2”) in consumer technology.
Empowerment promise State of the art ("web2") The promise ("web3") Governance How much say do you, the user, have in what the tech products do that you use? What about none! The developing companies do what they please, and very often the opposite of what their users want. Users are co-owners of the product, and have a vote through mechanisms such as DAOs. Identity You generally need at least an e-mail address hosted by some big platform to sign up for anything. Should the platform decide to close your account, even mistakenly, your identity effectively vanishes. Users are self-asserting their identity in a self-sovereign manner. We used to call this "user-centric identity", with protocols such as my LID or OpenID before they were eviscerated or co-opted by the big platforms. Glad to see the idea is making a come-back. Content ownership Practically, you own very little to none of the content you put on-line. While theoretically, you keep copyright of your social media posts, for example, today it is practically impossible to quit social media accounts without losing at least some of your content. Similarly, you are severely limited in your options for privacy, meaning where your data goes and does not go. You, and only you, decide where and how to use your content and all other data. It is not locked into somebody else's system. Ability to build Ever tried to add a feature to Facebook? It's almost a ridiculous proposition. Of course they won't let you. Other companies are no better. Everything is open, and composable, so everybody can build on each other's work. Exchange of value Today's mass consumer internet is largely financed through Surveillance Capitalism, in the form of targeted advertising, which has led to countless ills. Other models generally require subscriptions and credit cards and only work in special circumstances. Exchange of value as fungible and non-fungible tokens is a core feature and available to anybody and any app. An entirely new set of business models, in addition to established ones, have suddently become possible or even easy. As Jeremiah pointed out when we bumped into each other last night, public discussion of “web3” is almost completely focused on this last item: tokens, and the many ill-begotten schemes that they have enabled.
But that is not web3’s lasting attraction. The other four promises – participation in governance, self-sovereign identity, content ownership and the freedom to build – are very appealing. In fact, it is hard to see how anybody (other than an incumbent with a turf to defend) could possible argue against any of them.
If you don’t like the token part? Just don’t use it. 4 out of the 5 web3 empowerment promises for people, ain’t bad. And worth supporting.