-
2025-06-02
The Orb / Tools for humanity / Worldcoin in 5 min

“The Orb” is popping up in all sorts of places, most recently in Time magazine’s “The Orb Will See You Now”. It’s being heralded as everything from the one and final solution for privacy-protecting digital identity online, to a civil liberties nightmare, to an indispensable tool for preventing an AI takeover, to a quick way to make $42, and more.
But what it actually does and how it works is remarkably hard to find out. In a recent podcast, the team behind the project took more than two hours to explain it, and that was only the highlights with no detail. No wonder theories are all over the place.
I listened to that podcast, and I think I can explain it in 5 min. Read on, and we’ll start at the place where the value occurs: the Relying Party.
“Relying Party” is a geek term for a website or app into which you want to log in. So: all the value of the Orb and the app and networks and all of that is because users can log into websites or apps with this system (which doesn’t even have a good name. It’s not the Orb, which in the grand scheme of things is not important. It’s not the World Coin. Maybe it’s the World Network, but that name is so bland to be almost useless. I’m going to call it WN for this post.)
So you can log into a website or app with WN. That feature is of course not unique. You can log into websites or apps with other things, like usernames and passwords, or your Google or Facebook account or OpenID. But unlike other ways of logging in, if you log into a website or app with WN, the website or app is being guaranteed by all the tech that WN throws at it that a user who already has an account on the website or app they want to log in, cannot make a second account for the same website or app.
Have multiple Reddit accounts? Multiple Gmail addresses? Or multiple Amazon accounts? If those sites were to implement WN, you could not do that. Instead, those sites could be fairly certain that any new account created on their site was 1) created by a human and 2) each account was created by a different human. (Actually, the site can let you create multiple accounts, but only if it knows that all of them belong to you. You cannot create separate accounts pretending to be two distinct humans. So I lied, you could have multiple Reddit accounts, but you could not hide that fact from Reddit.)
I don’t want to talk about here why this may be a good or a bad idea. Only how this is done.
Secondly, if you log into two separate sites with WN, the two sites cannot compare notes and track you from one site to the other. Unlike with, say, logging in by e-mail address, the two sites cannot simply compare the e-mail addresses you gave them, and say, Oh, it’s the same Joe! Let’s show him underware ads on this site too, because he browsed underwear on the first site. That is impossible because he two sites are being given different identifiers. (Those seem to be public keys, so there is a different key pair per site.) This is nice from a privacy perspective, similar to what Kim Cameron popularized twenty years ago with directed identity.
The site-specific key pairs are being generated from the single most important piece of data in the system, which is your master public key, stored on a blockchain. This public blockchain acts as a registry for all the identities in the system, i.e. for all humans registered with WN – but before your freak out, it’s not as bad as it sounds, because all that the blockchain stores is a public key. There is no other information on that blockchain or elsewhere associated with that key, such as your name or blood type. It’s just a long basically random number.
So: the blockchain lists all the public keys of the people whose identity can be asserted by WN, and the technical machinery can derive relying-party-specific keypairs from any of those so that the relying party can be certain the user has been verified, but cannot tell which of the public key on the block chain, or which other keys used with other sites belong to the same user.
How does the key get onto that block chain? It appears there is a small set of trusted actors that have the credentials to put keys onto that blockchain, and that small set of trusted actors are the Orb stations WN has been setting up all over the world to get people registered. The actual keys being registered are generated on your mobile device, and only the public key is given to the system, the private one remains on your device only.
So the Orb only exists to make a decision whether or not a public key you’ve created on your mobile device may or may not be added to the registry of verified identities on that blockchain. That’s all. The key decision the Orb (and all of its Orb siblings in other locations) need to make is: have any of us registered that human before? If yes, do not add their new key to the blockchain. If no, let’s add it.
To determine whether or not WN has registered you before, the Orb (really just a fancy camera) takes a picture of your retina, figures out its unique characterics, breaks them into a gazillion data shards (which are entirely useless until you have brought all of them together – modern cryptography is often counter-intuitive) and distributes them so that it is hard to bring it back together. When somebody attempts to register again, the new attempted registration does the same thing, but the system rejects it (using some fancy multi-party computation distributed over 3 universities) because the previous shards are there already.
That’s it. (Plus a few add-on’s they have been building. Like verifying, using your smartphone’s camera, that it is indeed you operating the device when you are attempting to log into a site or app, so you can’t simply hand your public key to another person who otherwise could amass or buy thousands of other people’s identities and effectively create thousands of accounts on the same site, all under their control. Or the crypto currency that the relying party has to pay in order to get WN to verify an authentication attempt – that pays the sign-up bonus from for new users, plus for the operation of the network.)
My impression:
Lots of tech and smarts. I have not looked at the algorithms, but I can believe that this system can be made to work more or less as described. It has a clearly unique value proposition compared to the many other authentication / identity systems that are found in the wild.
My major remaining questions:
-
How does this system fail, and how would it be fixed if/when it does? You can be 100% certain of attacks, and 100% certain of very sophisticated attacks if they get substantial uptake. I have no good intuition about this, and I haven’t seen any substantive discussion about that either. (That would probably take a lot more than a two-hour podcast.) Given that one of their stated goal is that in the longer term no organization, including themselves, can take over the system, how would a rapid fix for a vulnerability even work?
-
And of course: will anybody adopt it? Tech history is full of failed novel authentication systems – the above quoted Kim’s CardSpace, in spite of being shipped with every copy of Windows, being a notable example. And there I have my doubts. As it is famously said, whatever your authentication or identity scheme, the first thing that a relying party asks for when implementing any of them is your e-mail address. If they continue to do that, the whole system would be largely pointless. But maybe there are some niche applications where this is different, I just haven’t seen many of them.
P.S. I’m sure I got some details wrong. Please correct me if you know better.
-
-
2024-08-09
Notes from our DWebCamp session imagining the future of open social networking
At this year’s, DWebCamp, my friend and collaborator Kaliya aka IdentityWoman and I ran a session titled:
We did something that, at least for me, was new. We started with:
- Assume it has happened. We have won. Like on page 1 of a sci-fi story, you wake up in the morning one day and the world you want is has suddenly arrived.
- At least 4 billion people interact with each other socially on an open, decentralized social network. All of the proprietary platforms have much smaller user numbers or have disappeared entirely; they have stopped mattering.
- Out of scope: how we get there, or which specific products/standards/technologies are being used.
We asked the question: “Describe what you see”. People who came to our session had a few minutes to meditate on that question, and then wrote down their thoughts, one at a time, on some stickies. They then announced what they wrote and put it on a big sheet of paper. Below is the electronic version of this paper (minus some items which I could not manage to decipher when transcribing):
Community focused and developed by the communityHate free zoneAccessible resources (open source) for development by anyoneMessage flows automatically (I don’t have to decide who are the recipients)biofi.earth for decentralized technologyNot harmfully poweredAccess to all medical data. Do I want all measurements? Which doctor may see what? How do I manage that?Serependipity / surprise meAnti-filter bubbleMulti-modal “of one universe”Everything is forkable (in the open-source sense)Everything is fully transparentAttention management / needs to managePersonal and collective sense-making bubbleStigmergy / people markingHow to make the network safe?Non-screen-centric“Netflix”-like subscription for all: distributed to builders / operatorsNew funding models for open sourceCooperative Attention EconomyFed by opt-in-able data setsAbility to opt-in/opt-outPersonal digital exoskeleton / voice-centricNot one systems. Highly fragmented (needs are specific)A shared collaborative universe, not just “apps”Social “digital twin” objectsWho you are is what you consume: food and informationPhoto galleryIf it isn’t worth looking at for at least 10 seconds, it isn’t worth any time at allTap to dive in, call, play, study / zoom out to explore and connectNon-repetitiveProfile: Skills Expanse Reviews Map Faves MusicCorporate news is dead, replaced by emergent editorial boardsThreats community mapping / fearWhat surprised me most is that there were so many comments that wanted to have a single “social universe” into which various apps and screens and voice are “windows”", rather than a single app. That’s very close to the original vision for the world-wide-web, and one that we’ve largely lost with all the apps we are using every day. But perhaps we can get it back?
Addition 2024-08-17: two more, which I don’t know how to transcribe.
-
2024-01-19
I can’t remember any time when more spaces for innovation and entrepreneurship were wide open than now
Lenin supposedly said:
There are decades where nothing happens, and there are weeks where decades happen.
It’s the same in technology.
I came to Silicon Valley in the mid-90’s, just in time to see the dot-com boom unfold. Lots happened very quickly in that time. There were a few more such periods of rapid change since, like when centralized social media got going, and when phones turned into real computers. But for many years now, not much has happened: we got used to the idea that there’s a very small number of ever-larger tech giants, which largely release incremental products and that’s just that. Nothing much happens.
But over the last year or so, suddenly things are happening again. I think not only are the spaces for innovation and entrepreneurship now more open than they have been for at least a decade or more; it’s possible they have never been as open as they are now.
Consider:
-
Everybody’s favorite subject: machine learning and AI. I don’t believe in much of what most people seem to believe about AI these days. I’m not part of the hype train. However, I do believe that machine learning is a fundamental innovation that allows us to program computers in a radically different way than we have in the past 50 and more years: instead of telling the computer what to do, we let it observe how it’s done and have it copy what it saw. Most of what today’s AI companies use machine learning for, in my view, is likely not going to stand the test of time. However, I do believe that this fundamentally different way of programming a computer is going to find absolutely astounding and beneficial applications at some point. It could be today: the space for invention, innovation and entrepreneurship is wide open.
-
The end of ever-larger economies of scale and network effects in tech. The dominant tech companies are very close to having pretty much all humans on the planet as customers. The number of their users is not going to double again. So the cost structure of their businesses is not going to get reduced any more simply by selling the same product to more customers, nor is the benefit of their product going to grow through growing network effects as much as in the past. It’s like they are running into a physical limit to the size of many things they can do. This opens space for innovation and successful competition.
Most interesting, it allows the creation of bespoke products again; products that are optimized for particular markets, customer groups and use cases. Ever noticed that Facebook is the same product for everybody, whether you are rich or poor, whether you have lots of time, or none, whether you are CEO or a kid, whether you like in one place or another, whether you are interested in sports or not and so forth? It’s the same for products of the other big platform vendors. That is a side effect of the focus on economies of scale. All of a sudden, increased utility for the user will need to come from serving their specific needs, not insisting that all cars need to be black. For targeted products, large platforms have no competitive advantages over small organizations; in fact, they may be at a real disadvantage. Entrepreneurs, what are you waiting for?
-
The regulators suddenly have found their spine and aren’t kidding around, starting with the EU.
-
The Apple App Store got in the way of your business? They are about to force the App Store open and allow side loading and alternate app stores (although Apple is trying hard to impede this as much as possible; a fight is brewing; my money is on the regulators).
-
The big platforms hold all your data hostage? Well, in many jurisdictions around the world you now have the right to get all copy of all your data. Even better, the “continuous, real-time access” provision of the EU’s Digital Markets Act is about to come into force.
-
The platforms don’t let you interoperate or connect? Well, in the EU, a legal requirement for interoperability of messaging apps is already on the books, and more are probably coming. Meta’s embrace of ActivityPub as part of Threads is a sign of it.
Imagine what you can do, as an entrepreneur, if you can distribute outside of app stores, use the same data on the customer that the platforms have, and you can interoperate with them? The mind boggles … many product categories that previous were impossible to compete with suddenly are in play again.
-
-
Social networking is becoming an open network through the embrace of ActivityPub by Meta’s Threads. While nobody outside of Meta completely understands why they are doing this, they undoubtedly are progressing towards interoperability with the Fediverse. Whatever the reasons, chances are that they also apply to other social media products, by Meta and others. All of a sudden competing with compelling social media application is possible again because you have a fully built-out network with its network effects from day one.
-
Consumers know tech has a problem. They are more willing to listen to alternatives to what they know than they have in a long time.
-
And finally, 3D / Spatial Computing a la Apple. (I’m not listing Meta here because clearly, they don’t have a compelling vision for it. Tens of billions spent and I still don’t know what they are trying to do.)
Apple is creating an an entirely new interaction model for how humans can interact with technology. It used to be punch cards and line printers. Then we got interactive green-screen terminals. And then graphics displays, and mice. That was in the 1980’s. Over the next 40 years, basically nothing happened (except adding voice for some very narrow applications). By using the space around us as a canvas, Apple is making it possible to interact with computing in a radically different way. Admittedly, nobody knows so far how to really take advantage of the new medium, but once somebody does, I am certain amazing things will happen.
Again, an opportunity ripe for the taking. If it works, it will have the same effects on established vendors as the arrival of the web had on established vendors: some managed to migrate, or the arrival graphical user interfaces on the vendors of software for character terminals; most failed to make the switch. So this is another ideal entrepreneurial territory.
But here’s the kicker: what if you combined all of the above? What can you build if your primary interaction model is 3D overlayed over the real world, with bespoke experiences for your specific needs, assisted by (some) intelligence that goes beyond what computers typically do today, accomplished by some form of machine learning, all fed by personal data collected by the platforms, and distributed outside of the straightjacket and business strategies of app stores?
We have not seen as much opportunity as this in a long time; maybe ever.
-
-
2023-12-08
Meta/Threads Interoperating in the Fediverse Data Dialogue Meeting yesterday
I participated in a meeting titled “Meta’s Threads Interoperating in the Fediverse Data Dialogue” at Meta in San Francisco yesterday. It brought together a good number of Meta/Threads people (across engineering, product, policy), some Fediverse entrepreneurs like myself, some people who have been involved in ActivityPub standardization, a good number of industry observers / commentators, at least one journalist, and people from independent organizations whose objective is to improve the state of the net. Altogether about 30 people.
It was conducted under the Chatham House rule, so I am only posting my impressions, and I don’t identify people and what specific people said. (Although most attendees volunteered for a public group photo at the end;
I will post a link when I get one.Photo added at the bottom of this post.)For the purposes of this post, I’m not going to comment about larger questions such as whether Meta is good or bad, should be FediBlock’ed immediately or not; I’m simply writing down some notes about this meeting.
In no particular order:
-
The Threads team has been doing a number of meetings like this, in various geographies (London was mentioned), and with various stakeholders including the types of people that came to this meeting, as well as Fediverse instance operators, regulators and civil society.
-
Apparently many (most?) invitees to these meetings were invited because other invitees had been recommending them. I don’t know whether or what kind of future meetings like this they are planning, but I’d be happy to pass along names if we know each other and you get in touch. Thanks to – you know who you are – who passed along my name.
-
The Threads team comes across as quite competent and thoughtful at what they do.
-
On some subjects that are “obvious” to those of use who have hung around open federated systems long enough like myself, many attendees seemed strangely underinformed. I didn’t get the impression that they don’t want to know, but simply that integrating with the “there-is-nobody-in-charge” Fediverse is so different from other types of projects they have done in the past, they are still finding their bearings. I heard several: “A year ago, I did not know what the Fediverse was.”
-
Rolling out a large node – like Threads will be – in a complex, distributed system that’s as decentralized and heterogeneous as the Fediverse is not something anybody really has done before. It’s unclear what can go wrong, so the right approach appears to be to go step-by-step, feature by feature: try it, see how it works in practice, fix what needs fixing, and only then move on to the next feature.
-
That gradual approach opens them up to suspicions their implementation is one-sided and entirely self-serving. I guess that can’t be avoided until everything is deployed they publicly said they will deploy.
-
While there are many challenges, I did get the impression the project is proceeding more or less as planned, and there are no major obstacles.
-
Everybody knows and is aware Meta brings a “trust deficit” to the Fediverse. The best mitigation mentioned was to be as transparent as possible about all aspects of what they plan and do.
I think that’s a good approach, but also that they can do far more on transparency than they have so far. For example, they could publicly share a roadmap and the engineering rationale for why the steps they identified need to be in this sequence.
-
There are many, many questions on many aspects of the Fediverse, from technical details, to operational best practices, to regulatory constraints and how they apply to a federated system. The group generally did not know, by and large, how to get them answered, but agreed that meetings like this serve as a means to connect with people who might know.
I think this is a problem all across the Fediverse, not specific to Meta. We – the Fediverse – need to figure out a way to make that easier for new developers; certainly my own learning curve to catch up was steeper than I would have liked, too.
-
Many people did not know about FediForum, our Fediverse unconference, and I suspect a bunch of the meeting attendees will come to the next one (likely in March; we are currently working on picking a date). Many of the discussions at this meeting would have been right at home as FediForum sessions, and while I am clearly biased as FediForum organizer, I would argue that doing meetings like this in an open forum like FediForum could help substantially with the trust deficit mentioned above.
-
There’s significant interest in the Fediverse Test Suite we just got funding approval for from the EU’s NGI Zero program. There’s general agreement that the Fediverse could work “better”, be more reliable, and more be comprehensible to mainstream users, if we had better the test coverage than the Fediverse has today. This is of interest to all new (and existing) developers.
-
There was a very interesting side discussion on whether it would be helpful for Fediverse instances (including Threads) to share reputation information with other instances that each instance might maintain on individual ActivityPub actors for its own purposes already. Block lists as they are shared today are a (very primitive) version of this; a more multi-faceted version might be quite helpful across the Fediverse. This came up in a breakout group discussion, and was part of brainstorming; I didn’t hear that anybody actually worked on this.
-
When we think of privacy risks when Meta connects to the Fediverse, we usually think of what happens to data that moves from today’s Fediverse into Meta. I didn’t realize the opposite is also quite a challenge (personal data posted to Threads, making its way into the Fediverse) for an organization as heavily monitored by regulators around the world as is Meta.
-
There was very little talk (not none, but little) about the impact on regulation, such as the “continuous and real-time access” provision in the EU’s Digital Markets Act and whether that was a / the driver for Fediverse integration.
-
There was very little discussion on business models for Threads, and where exactly ads would go. For example, would ads just stay within the Threads app, or would they inject them into ActivityPub feeds, like some companies did with RSS back in the days? Of course, should that happen, as a non-Threads Fediverse user, one can always unfollow; there is no way for them to plaster non-Threads users with ads if they don’t interact with Threads accounts.
-
I came away convinced that the team working on Threads indeed genuinely wants to make federation happen, and have it happen in a “good” way. I did not get any sense whatsoever that any of the people I interacted were executing any secret agenda, whether embrace-and-extend, favoring Threads in some fashion or anything like that. (Of course, that is a limited data point, but I thought I convey it anyway.)
-
However, the meeting did not produce a clear answer to the elephant-in-the-room question that was raised repeatedly by several attendees in several versions, which is some version of: “All the openness with Threads, namely integration with the Fediverse, supporting account migration out from Threads etc, is the opposite of what Facebook/Meta has done over its history. What has fundamentally changed so that you now believe openness is the better strategy?” And: “In the past Facebook was a far more open system than it is today, you gradually locked it down. What guarantee is there that your bosses won’t follow the same playbook this time, even if you think they won’t?”
Personally I believe this question needs a better answer than has been given publicly so far, and the answer needs to come from the very top of Meta. The statement must have staying power beyond what any one executive can deliver.
I left the meeting with far more questions than I could get answered; but nobody wanted to stay all night :-)
My gut feel is that it is safe to assume they will do a reasonably fair, responsible job with a gradual rollout of federation for at least the next year or two or such. Beyond that, and in particular if it turns out creators with large follower groups indeed move off Threads at a significant rate (one of the stated reasons why they are implementing Fediverse support as creators have asked for this), I don’t think we know at all what will happen. (I’m not sure that anybody knows at this point.) And of course, none of this addresses the larger issues that Meta has as an organization.
In the hope this summary was useful …

(Source. Thanks tantek.com for initiating this.)
-
-
2023-09-22
Fediverse Testsuite Slides from FediForum
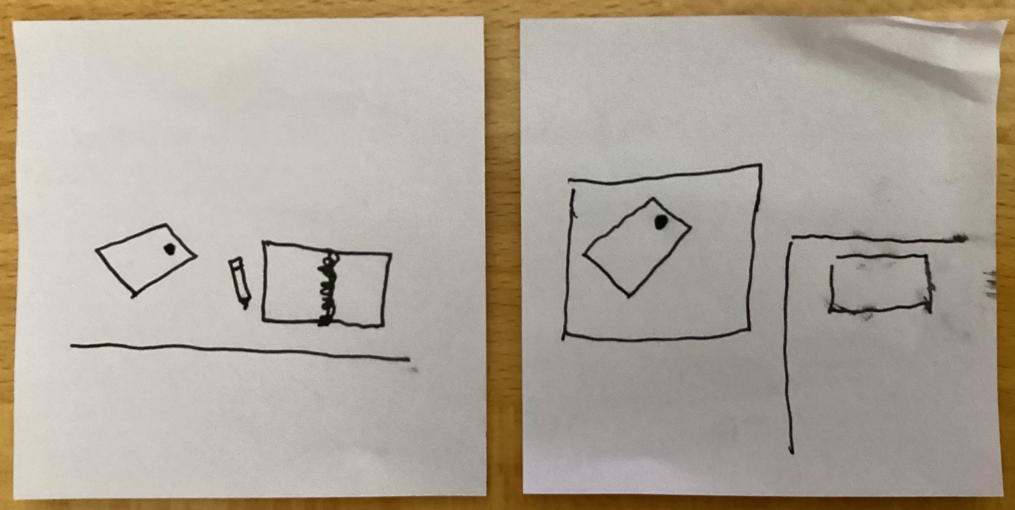
Here are the two slides I showed at FediForum to help with the discussion on a possible Fediverse test suite.

-
2023-08-16
The Peer Computing Architecture
I used that term frequently a long time ago, before the centralizing platforms took over all of technology. I believe it’s time to dig it back out, because for the first time in over a decade, perhaps even two, there’s real uptake in this computing architecture with protocols such as ActivityPub and Matrix.
My definition is at peercomputing.org.
Feedback appreciated.
(Historical note: there was a time I called it the “four-point architecture”. My old blog tells me I wrote about it in, gasp, 2005. That means 18 years of walking in the desert, and only now do the doors open up again.)